
Summarizing very large documents poses unique challenges for NLP and large language models (LLMs). Standard approaches often split the text into smaller chunks and summarize each piece, then merge those summaries. While this basic chunk-and-merge strategy (also known as a Map-Reduce summarization) works, it can struggle with coherence and context loss (How to summarize large Research articles? – API – OpenAI Developer Community) (Summarisation Methods and RAG | Continuum Labs). This report explores advanced methods beyond simple chunking, focusing on open-source models and practical techniques. We cover strategies to handle texts exceeding context windows, hierarchical and recursive summarization, retrieval augmentation, input compression, and memory-augmented architectures. Implementation details, algorithms, and tools are discussed with examples and references.
Challenges in Summarizing Long Texts
LLMs have a fixed context window (the maximum tokens they can process in one go). Any document longer than this must be handled specially. For example, GPT-4 (32K version) can take tens of thousands of tokens, and some state-of-the-art models claim up to 100K or even 1M token contexts (How to Summarize Large Documents with LangChain and OpenAI). However, simply extending context isn’t a panacea – models exhibit primacy and recency effects, overweighting the beginning or end of the input (How to Summarize Large Documents with LangChain and OpenAI). This means important information in the middle of a long text might be overlooked if we naively feed a huge sequence. There’s also computational cost: processing hundreds of thousands of tokens in one pass is extremely expensive (How to Summarize Large Documents with LangChain and OpenAI). In summary, key challenges include:
- Context Limitations: Base LLMs can’t directly ingest texts longer than their context size, requiring us to break or compress inputs.
- Maintaining Coherence: Splitting text can lose cross-chunk context. Ensuring the final summary is coherent and not disjoint is non-trivial.
- Information Loss: Summarizing in parts risks dropping details or missing global themes that span chunks.
- Bias in Long Inputs: Even with extended context models, long inputs can introduce positional biases (primacy/recency) (How to Summarize Large Documents with LangChain and OpenAI).
- Efficiency: Long-document summarization can be slow and costly, motivating methods to reduce the token load without losing key content.
With these challenges in mind, we next discuss advanced strategies to summarize long texts effectively.
Extended Context Models and Strategies
One approach is to extend the model’s context window or use architectures designed for long sequences. Recent research and open-source efforts have produced models that handle long inputs natively:
- Efficient-Attention Transformers: Models like Longformer and BigBird modify the Transformer’s self-attention to be sparse or structured, enabling inputs of thousands of tokens (GitHub – huankoh/long-doc-summarization: Long Document Summarization Papers). For example, Longformer uses local attention patterns and global tokens to handle sequences up to 4K or more, and BigBird introduces block sparse attention (both were used for long document tasks including summarization).
- Long-Document Encoder-Decoders: The Longformer was extended into an encoder-decoder called LED (Longformer Encoder-Decoder). The open model
allenai/led-large-16384can directly summarize documents up to 16,384 tokens (Led Large Book Summary · Models · Dataloop). Similarly, Pegasus-X and LongT5 are variants of Pegasus and T5 tuned for long inputs (8K+ tokens) (GitHub – huankoh/long-doc-summarization: Long Document Summarization Papers). - Position Encoding Tricks: Techniques like ALiBi (Attention Linear Bias) or position interpolation allow standard LLMs to generalize to longer contexts than seen in training. MosaicML’s MPT-7B-StoryWriter is a fine-tuned 7B model with a 65k token context; thanks to ALiBi it can even extrapolate to ~84k tokens at inference (mosaicml/mpt-7b-storywriter · Hugging Face). This demonstrates that with fine-tuning and clever positional embeddings, even GPT-style models can handle super long inputs.
- Proprietary Large-Context Models: While focusing on open source, it’s worth noting that Anthropic’s Claude models can accept up to 100k tokens, and OpenAI’s GPT-4 offers a 32k context version. These use internal optimizations (and lots of memory) to handle long documents in a single pass. They are often used for summarizing books or lengthy transcripts without chunking.
- State-Space and Other Architectures: Beyond transformers, research into state-space models (e.g. S4, SSR) and hybrids (like Hyena) aims to handle long sequences with linear memory/time complexity. These are experimental but point toward future open models that might handle entire books end-to-end.
Using an extended-context model means you might not need to chop the text at all – you feed the whole text and get a summary. This preserves global coherence and context. For instance, an LED-based summarizer can input a full academic paper and produce an abstractive summary in one shot. However, keep in mind the trade-offs: very long context processing can be slow, and models might still not utilize all that context effectively (as shown by studies like “Lost in the Middle”, which found that models often underuse the middle parts of long inputs (GitHub – huankoh/long-doc-summarization: Long Document Summarization Papers)). Thus, extended context is powerful but often combined with other strategies for best results.
Hierarchical and Recursive Summarization
When a document far exceeds the context limit, a structured hierarchical summarization approach can maintain coherence. The idea is to recursively summarize in stages, mirroring the document’s structure (sections, chapters, etc.) (How to summarize large Research articles? – API – OpenAI Developer Community). Rather than just splitting randomly, this approach creates a summary pyramid:
- Section-wise Summaries: If the text has natural sections (chapters in a book, sections in a report), summarize each section independently. This ensures each part’s main points are captured. For example, summarize each chapter of a book into a paragraph.
- Summary of Summaries: Next, take the collection of section summaries and summarize them together to produce a higher-level summary (How to summarize large Research articles? – API – OpenAI Developer Community). This second-layer summary should capture the overall themes using the section summaries as input. You can even continue this process if needed (e.g., summarize chapter groups, then the whole book).
- Hierarchical Structure Leverage: This method leverages the document’s inherent organization. If a report has introduction, methods, results, conclusion, you can get a concise summary of each and then an overall summary. This typically yields a more organized and coherent final summary than arbitrary chunking, since the final stage is aware of each section’s gist.
Example – Book Summarization: Imagine a 300-page novel. A hierarchical approach might split it by chapters: each chapter (~10-15 pages) is within the LLM’s context window. You prompt the LLM to summarize each chapter. Then you feed the list of chapter summaries into the LLM (in multiple passes if needed) to get a summary of the entire book’s plot and themes. This two-level summary retains the narrative flow better than summarizing random 2048-token chunks.
This divide-and-conquer strategy was validated in practice. As one developer noted, using “summaries of summaries” tends to produce more coherent results than a single-pass over chunked text (How to summarize large Research articles? – API – OpenAI Developer Community). Hierarchical methods were also used in research – e.g., HAT (Hierarchical Attention Transformer) introduced extra attention layers that learn paragraph-level representations on top of token-level, effectively implementing a hierarchical read of long texts ([2104.07545] Hierarchical Learning for Generation with Long Source Sequences). Hierarchical approaches ensure each stage abstracts further, which prevents overly detailed info from overwhelming the final summary (How to summarize large Research articles? – API – OpenAI Developer Community).
Map-Reduce vs. Iterative Refinement
There are two common patterns for hierarchical summarization:
- Map-Reduce Summarization: This is the summaries of chunks then summary-of-summaries approach described above. Each chunk is summarized independently (the “map” step), and then those summaries are merged (the “reduce” step) into a final summary (Summarisation Methods and RAG | Continuum Labs). This can be done in multiple layers if needed (e.g., summarize paragraphs, then summarize those into section summary, then to full summary). Map-reduce is easily parallelizable (since each chunk is summarized independently) and ensures coverage of the whole text. However, the final merged summary might contain some redundancy or lose some context that spans chunks (Summarisation Methods and RAG | Continuum Labs).
- Iterative Refinement (Refine Chain): Instead of summarizing all parts independently, the model can build the summary progressively. For example, start by summarizing the first chunk. Then for each subsequent chunk, ask the LLM to update or expand the existing summary with information from the next chunk (How to summarize large Research articles? – API – OpenAI Developer Community). Essentially the LLM refines the summary as it reads more of the text, rather than producing separate pieces. LangChain refers to this as the “Refine” summarization chain. It maintains better continuity since the summary carries forward, at the cost of being sequential (no parallel speed-up) (Summarisation Methods and RAG | Continuum Labs). The refine method can sometimes preserve context and reduce redundancy better than map-reduce because the model always considers the current summary state when adding new information. On the downside, errors or omissions early on might persist, and the final summary might overly favor earlier chunks if not prompted carefully to adjust.
Both strategies have merits, and they can even be combined (e.g., do map-reduce for subsections, then a refine pass over section summaries). These approaches are essentially more sophisticated variants of chunk-and-merge, using recursion or memory to keep the final output coherent.
Sliding Window for Overlap
Another refinement to basic chunking is using a sliding window with overlap. Instead of disjoint chunks, we process overlapping segments of the text and generate partial summaries for each window. For example, take 50% overlapping windows of, say, 1000 tokens. Each window’s summary will share context with the next, which helps maintain continuity. After that, one could either merge these overlapping summaries or select the most relevant portions from each.
The sliding window approach addresses the problem where important content might fall on the boundary of a chunk. Overlapping ensures that content near chunk edges is seen in at least one of the windows with proper context. However, using overlapping windows means more summaries to merge and possibly more redundancy. One must post-process carefully, perhaps by selecting the most relevant sentences from each window’s summary or doing another summarization pass on the combined summaries (How to summarize large Research articles? – API – OpenAI Developer Community).
In practice, sliding window is often combined with either refine or map-reduce. For instance, you might slide a window to generate overlapping chunk summaries, then feed those into a reduce step. This technique is a bit more complex, but it can yield a more fluent summary when preserving context is critical (such as summarizing a story or dialogue where events flow continuously).
Retrieval-Augmented Summarization
Retrieval-Augmented Generation (RAG) is typically used for question-answering with long documents, but the same idea can help summarization. The core idea is to use a vector database or search index to fetch the most relevant pieces of the text for the summarizer, instead of feeding the entire text at once. This becomes useful when dealing with extremely large corpora or multi-document summarization.
Key approaches for retrieval-based summarization:
- Chunk Indexing: First, split the long text into chunks (e.g., paragraphs or sections) and encode them into vector embeddings (using a model like Sentence-BERT or an embedding from an LLM). Store these in a vector database (FAISS, Milvus, etc.) with references to the original text. Now, instead of blindly summarizing everything, formulate a prompt or query for the summary. For example, use a query vector for “overall summary of document X” or simply treat it as an information retrieval task where the “query” is the notion of important content.
- Retrieving Key Passages: Using similarity search or Maximal Marginal Relevance (MMR), retrieve a subset of chunks that cover the document’s main ideas with minimal redundancy. MMR is a reranking technique that maximizes relevance to the query while ensuring diversity (reducing overlap) (Maximum Marginal Relevance (MMR) – Full Stack Retrieval) ([2503.09249] Considering Length Diversity in Retrieval-Augmented Summarization). By applying MMR or a related algorithm, we can pick a set of chunks that collectively represent the document’s content. Recent research on retrieval-augmented summarization introduced methods like DL-MMR (Diverse Length-aware MMR) to better control which snippets are selected under length constraints ([2503.09249] Considering Length Diversity in Retrieval-Augmented Summarization) – essentially aiming for a set of passages that cover all key points without being too similar to each other.
- Summary Generation with Retrieved Context: Once relevant segments are retrieved, concatenate them (if they fit in context) or summarize those first if they are still too many. Then prompt the LLM to generate a summary using only that distilled set of passages. This focuses the LLM on the most salient parts of the text, rather than burdening it with every detail. It’s a form of content filtering – the model sees supportive evidence for main points, which can improve efficiency and possibly factuality.
An example of this approach: suppose you have a 200-page annual report. You chunk it into paragraphs and store embeddings. You then ask, “What are the key findings and conclusions of this report?” The system uses this as a query, retrieves, say, 20 paragraphs that seem most related to conclusions and key findings (ideally from across the report). Then those 20 paragraphs are given to the LLM to summarize. The result should be a decent high-level summary focusing on the main points, as the retrieval step bypassed large swathes of less relevant detail.
One must be careful that important content isn’t missed during retrieval. Techniques like increasing the number of retrieved chunks or ensuring diversity (so that different sections of the document are represented) help. In practice, a “database of chunks and summaries” can be maintained (Summarisation Methods and RAG | Continuum Labs) – meaning you might store both the full chunk and a precomputed summary of each chunk. Then, a summarization query could retrieve either raw chunks or their summaries depending on needs. For instance, an interactive system could retrieve a quick summary from the summary-store for speed, but drill down to the full chunk if more detail is needed (Summarisation Methods and RAG | Continuum Labs).
Retrieval for Multi-Document: If the task is to summarize multiple documents (e.g., a collection of articles), retrieval is almost essential – you’d index all documents and retrieve top relevant parts for each aspect of the summary. This turns into a hybrid of summarization and search, where the system “chooses” what to summarize. Some recent pipelines do this with the help of agents that decide what to read next. For example, an agent can iteratively ask questions about the text and retrieve answers, gradually building a summary. This is beyond static summarization, but it’s an emerging idea (agent-based RAG) (Summarisation Methods and RAG | Continuum Labs).
In summary, retrieval-augmented summarization helps handle very large texts by focusing on important pieces. It can be combined with hierarchical methods (e.g., first retrieve salient chunks, then apply a hierarchical summarizer on those). The downside is that it requires setting up a vector index and possibly tuning the retrieval algorithm so that nothing critical is omitted. But it offers a powerful way to get around context limits by treating the text like a searchable knowledge base.
Pre-Processing and Compression Techniques
Before feeding text to an LLM, we can often pre-compress or filter the content so that only the most essential information remains. These compression techniques reduce the token count, making the summarization easier and cheaper for the model, and often improving the quality by removing noise.
Here are common approaches:
- Extractive Summarization as a First Step: Traditional NLP summarization (pre-LLM) often used extractive methods – picking sentences or paragraphs directly from the text that cover the main ideas. We can employ these to trim a long document. For instance, algorithms like TextRank (graph-based ranking of sentences) or neural extractive models (e.g., BertSumExt) will select a subset of important sentences. This reduced text can then be given to the LLM to rewrite abstractively. The risk is that if the extractive step misses something, the LLM never sees it, but if well-tuned, this can cut down a document dramatically. Recent research (e.g., MemSum ([2107.08929] MemSum: Extractive Summarization of Long Documents Using Multi-Step Episodic Markov Decision Processes) and SSN-DM (GitHub – huankoh/long-doc-summarization: Long Document Summarization Papers) for long documents) has looked at intelligently selecting sentences using reinforcement learning or dynamic memory to maximize coverage and minimize redundancy.
- Text Filtering and Cleaning: Not everything in a document is relevant for a summary. For example, in scientific papers or legal documents, one might remove quotations, examples, or detailed data sections that are not needed in a high-level summary. Simple heuristics or rules can drop these parts. Another example: if summarizing a transcript, you might remove small talk or disfluencies. By cleaning the text, you effectively increase the density of information per token.
- Semantic Similarity Clustering: If a document is long because it’s repetitive or contains many redundant points (think of a lengthy report that revisits the same ideas), clustering can help. By embedding all sentences or paragraphs and clustering them (e.g., K-means), we can find groups of similar content. We might then select one representative from each cluster – ensuring each unique idea is represented once. This was demonstrated in a recent tutorial, where K-means clustering was combined with LLM summarization to condense a book: clustering identified key passages, which were then summarized, greatly reducing the token count while keeping all topics (How to Summarize Large Documents with LangChain and OpenAI). Essentially, clustering + selection yields a “brainstorming list” of important distinct points, which the LLM can then fuse into a coherent summary.
- Lead and Outline Extraction: For structured texts like news articles or academic papers, one can use the structure itself for compression. E.g., extract the thesis statement, the section headings, or the topic sentences of each paragraph to form a skeleton of the document. That outline can be fed to the LLM to expand into a summary, or the outline itself can be refined. This is a bit like manual summarization: identify the key points first.
- Keyword or Keyphrase Guided Summarization: Another trick is to run a keyword extraction (using TF-IDF or an embedding-based keyword extractor) to get the main topics, and then instruct the LLM to focus the summary on those topics. This indirectly compresses input by focusing attention.
In practice, these compression techniques often feed into the earlier methods. For example, you might first do an extractive summary of a 100-page document to get it down to 5 pages, then ask an LLM to produce a fluent abstractive summary from those 5 pages. The combination of extractive+abstractive can yield good results while staying within context limits. A concrete pipeline might be:
- Use a keyword-based extractor or TextRank to select, say, the top 20 sentences from the text.
- Join those sentences (perhaps reordering for logical flow) into a condensed input.
- Prompt the LLM: “Summarize the following highlights of the document… (condensed text)”.
This way, the LLM sees only the highlights and can produce a concise summary that hopefully covers everything important. The trade-off is that if the compression is too aggressive, some nuance could be lost. Therefore, sometimes these methods are used with a human in the loop or at least verified.
Memory-Augmented and Long-Sequence Architectures
A different angle to tackle long texts is to give the model some form of extended memory beyond the normal context window. Traditional LLMs treat each prompt independently, but what if the model could remember earlier parts of the text as it reads further? Several strategies and model architectures enable this:
- Recurrent Processing (Manual or via RNN): Before transformers, LSTM/RNN-based models handled long sequences by processing tokens sequentially and updating a hidden state. In theory, an LSTM can process an arbitrarily long text by streaming through it. In practice they have trouble with very long-range dependencies, but the concept of a recurrent summary is useful. We can simulate this with an LLM by feeding the text in parts and carrying over a “state.” For example, one could maintain a running summary or notes as we go through the text. Pseudocode for this might look like:

Here, the model incrementally refines a summary, effectively using the summary as a persistent state (memory) that carries over to the next chunk. This is an implementation of the earlier iterative refinement idea, and it mimics how a human might take notes section by section then polish them.
- External Memory via Vector Databases: We discussed using a vector store for retrieval, but it can also serve as an external memory in a continuous summarization process. For instance, as the model reads each chunk, it could store an embedding or summary of that chunk in a database. Later chunks could trigger retrieval of relevant earlier summaries if needed. This way, even if an earlier detail is out of the current context window, the model can “remember” it by looking it up. An example in conversational agents is using a summary vector of the conversation so far (Vector Summarisation to Improve LLM Long Term Memory – Community – OpenAI Developer Community) (Vector Summarisation to Improve LLM Long Term Memory – Community – OpenAI Developer Community). The same can apply to static text summarization: maintain a memory of what’s been summarized so far. One approach called dual-layer summarization creates a text summary and a compressed vector representation of the summary; the vector can be stored and reloaded to reconstruct context later (Vector Summarisation to Improve LLM Long Term Memory – Community – OpenAI Developer Community) (Vector Summarisation to Improve LLM Long Term Memory – Community – OpenAI Developer Community). This ensures essential info is retained even if the text summary gets lost or the context window moves on.
- Transformer-XL and Extended Attentive Models: Model architectures like Transformer-XL introduce a segment-level recurrence – after processing one segment of text, the model carries forward its hidden states (as a “memory”) to influence the next segment (Transformer XL: Beyond a Fixed-Length Context – GeeksforGeeks) (Transformer XL: Beyond a Fixed-Length Context – GeeksforGeeks). This allows the model to effectively have an unlimited context length by processing text in segments and chaining the memory. In summarization tasks, one could use Transformer-XL or similar to sequentially feed a long text; the model will treat it almost like one continuous sequence, remembering earlier parts via the recurrent state. Compressive Transformer (from DeepMind) took this further by compressing older memories to retain a longer history in a smaller form. These model designs are not yet common in off-the-shelf summarization systems, but they hint at how future LLMs might inherently handle very long inputs by default.
- Memory Networks and Episodic Summarizers: Some research has explored explicitly storing facts or sentences and using an external memory module to decide what to include in the summary. For example, the MemSum algorithm used an episodic Markov Decision Process to iteratively select sentences for an extractive summary, with awareness of what had been selected before (this is a form of memory to avoid repetition and ensure coverage) ([2107.08929] MemSum: Extractive Summarization of Long Documents Using Multi-Step Episodic Markov Decision Processes) ([2107.08929] MemSum: Extractive Summarization of Long Documents Using Multi-Step Episodic Markov Decision Processes). There are also older Memory Networks (from Facebook AI research) that could store and retrieve information with an attention mechanism – one could imagine a summarizer that stores each new piece of information and explicitly queries its memory when generating summary sentences, to decide if that info is already included or if something relevant is missing.
- Tool-augmented LLMs: In a practical sense, one can give an LLM a “tool” that acts as memory. For instance, an LLM could be instructed to use a
Recall()function that searches its notes (or a database of content) whenever it needs details from earlier text. This crosses into the area of LLM agents, but it’s relevant: the agent might decide to summarize part of the text and save that summary (tool: SaveNote), then later parts of the text, it can load those notes (tool: LoadNote) to incorporate into the final output. Frameworks like LangChain or GPT-Index (LlamaIndex) have patterns where the LLM can navigate a tree of summaries or call a retriever when needed, effectively giving it a memory beyond the prompt.
In summary, memory-augmented methods allow an LLM to handle long texts by breaking the reading process into manageable chunks but preserving information across chunks through some form of state or external storage. This is conceptually similar to how humans might pause and recall earlier sections while reading a long document. The implementations range from straightforward (iteratively updating a summary string) to sophisticated (architectures like Transformer-XL or external memory networks). These approaches help mitigate the fragmentation caused by context window limits, at the cost of more complex control logic or model designs.
Practical Implementation: Tools and Workflows
Thanks to an active open-source community, there are many tools and libraries to implement the above techniques:
- Hugging Face Transformers: This library provides easy access to models like BART, T5, Longformer, Pegasus, etc., many of which can be used for summarization. For instance, one can load
allenai/led-large-16384-arxiv(LED fine-tuned on scientific papers) and use it to summarize long texts. Below is a sample code snippet using an LED model for a long document:
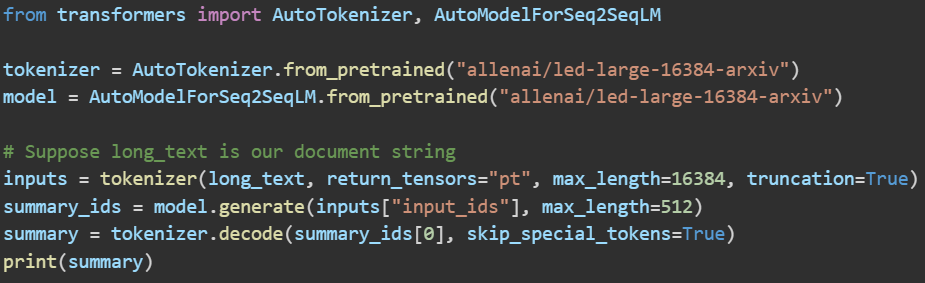
This example tokenizes a very long text (up to 16384 tokens) and generates a summary up to 512 tokens. Models like this make long-document summarization relatively straightforward if the text fits the model’s limit.
- LangChain Summarization Chains: LangChain provides chains for summarization that implement the strategies like map-reduce and refine out of the box (Summarize Text | ️ LangChain) (Summarize Text | ️ LangChain). You can configure a
load_summarize_chainwith your LLM of choice. For example, a map-reduce chain will automatically chunk the input, summarize each chunk (the “map” step, often done in parallel if using an async setup), then call a final LLM prompt to merge summaries. A refine chain will do an iterative approach, feeding each chunk in sequence along with the evolving summary. LangChain also has example selectors (like theMaxMarginalRelevanceSelector(Maximum Marginal Relevance (MMR) – Full Stack Retrieval)) that can pick informative chunks from a larger set – useful for retrieval-augmented summarization or to decide which chunks to summarize when you have more chunks than you can handle. - LlamaIndex (GPT-Index): This framework is designed for working with long data and LLMs. It allows building hierarchical indices: you can construct a tree index where leaves are chunks of the text and higher nodes store summaries of their children. Querying the index for a summary will traverse this tree, perhaps summarizing summaries along the way, which is essentially hierarchical summarization implemented recursively. LlamaIndex can also do keyword-based retrieval and has support for hybrid search and summarization pipelines. For example, you can build a vector index of a document and then ask LlamaIndex to give you a summary – internally it may retrieve top-k chunks and then summarize them. This abstracts a lot of the logic so you don’t have to code the retrieval + generation steps manually.
- Haystack: This is an open-source NLP framework that originally focused on QA over documents but also supports summarization pipelines. You can configure a preprocessor node to split text, then a summarizer node (which could be a transformer model from Hugging Face), and even a reducer node to combine summaries. It’s less end-to-end for abstractive summarization than LangChain or LlamaIndex, but it provides a robust way to manage document processing and might use extractive techniques to pre-filter content.
- Custom Pipelines: It’s not too difficult to implement custom strategies using Python and available models:
- For example, to implement a two-pass hierarchical summary, one could use a smaller/faster model for the first pass (to summarize chunks) and a larger model for the final pass. Code-wise, this might involve looping over
text_chunksto getchunk_summaries(with asummarizerpipeline or model.generate as above), then joining those summaries and feeding into the final model. - To experiment with retrieval, one can use libraries like
sentence-transformersto embed chunks,faissto perform similarity search, and then feed results to an LLM. This could be as simple as:
- For example, to implement a two-pass hierarchical summary, one could use a smaller/faster model for the first pass (to summarize chunks) and a larger model for the final pass. Code-wise, this might involve looping over
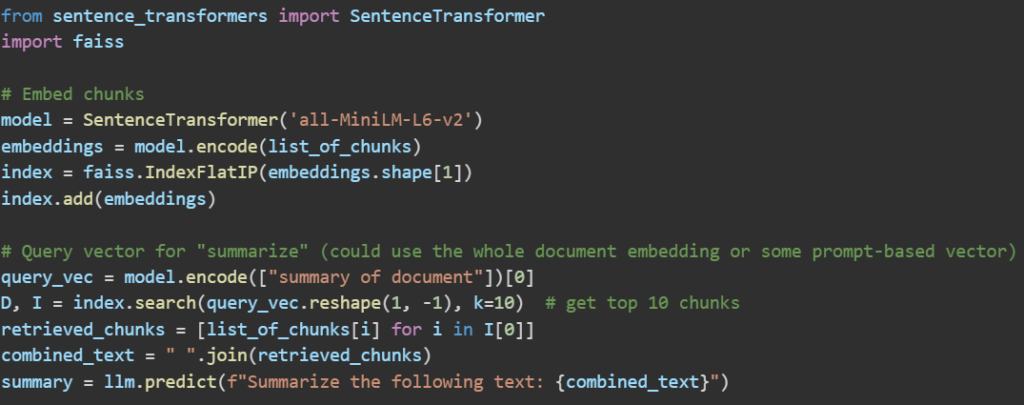
This code embeds all chunks, retrieves the top 10 most relevant to a generic summary query, and asks an LLM (via some .predict call, which could be an API or local model) to summarize the combined relevant chunks. In practice, you’d refine how the query is formed and possibly use MMR to ensure diversity in retrieval.
- Example: Map-Reduce via Prompting: If not using LangChain, you can still do a manual map-reduce. For instance:
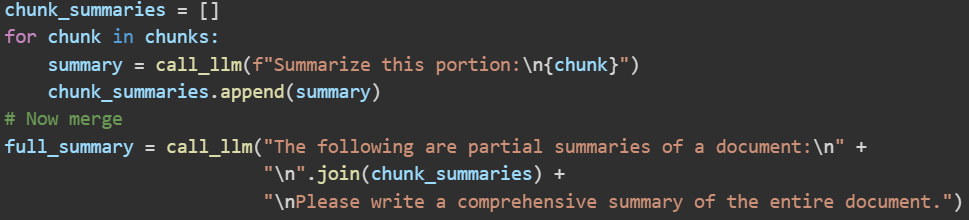
This demonstrates the logic. One would replace call_llm with the actual interface (could be an API call or using a transformer model). The prompt engineering can be more sophisticated, but the idea is straightforward.
- Dealing with Limits in Code: When implementing these, be mindful of token limits at each step. For example, when doing summary-of-summaries, the intermediate summaries should be short enough that all together they fit into the final prompt. You may need to restrict each chunk summary’s length (e.g., ask for 100 tokens each). Similarly, when doing iterative refinement, your prompt includes the current summary and the new chunk – ensure the prompt template plus expected output stay under the LLM’s limit each time.
Many of the above tools (LangChain, LlamaIndex) allow you to swap in open-source models easily – for example, using GPT4All or Llama-2 via HuggingFace instead of OpenAI’s API. Open-source models with ~7B or 13B parameters can often handle a few thousand tokens context, which is enough for moderate chunks. For truly large contexts, models like the 16k-token LED or the MPT-7B Storywriter (65k) can be integrated if you have the computational resources.
Conclusion
Summarizing long texts is a multi-faceted problem. Going beyond basic chunk-and-merge, we have explored how hierarchical techniques, retrieval augmentation, input compression, and memory mechanisms can significantly improve the quality and feasibility of long-document summarization. In practice, effective solutions often combine several of these approaches. For example, one might first compress or segment the text by importance, then apply a hierarchical summarization using an extended-context model, and perhaps use retrieval to double-check that no key point was missed. Open-source models and libraries provide a foundation to experiment with these methods – from specialized long-text models like Longformer/LED to frameworks like LangChain that implement map-reduce chains (Summarisation Methods and RAG | Continuum Labs) (Summarisation Methods and RAG | Continuum Labs).
In implementing these solutions, careful attention to detail is needed: designing prompts that guide the LLM at each stage, ensuring that intermediate summaries remain faithful, and evaluating the final output for completeness and coherence. Research is ongoing, with new innovations like length-aware retrieval algorithms ([2503.09249] Considering Length Diversity in Retrieval-Augmented Summarization) and hierarchical transformers pushing the boundaries of what’s possible. By combining the strengths of LLMs with smart NLP strategies, we can achieve high-quality summaries of texts that were previously too large or unwieldy to handle. The techniques outlined in this report should equip practitioners to build summarization pipelines that are both practical and powerful, leveraging large language models even when faced with truly large inputs.